58 同城深度学习平台,是集开发实验、模型训练和在线预测为一体的一站式算法研发平台,旨在为各业务部门赋能 AI 算法研发能力,支撑了 58 同城搜索、推荐、图像、NLP、语音、风控等 AI 应用。作为中国最大的生活信息服务商,58 同城不断在提高深度学习平台性能,提高平台资源使用率,从而更好的提升用户体验。

58 同城探索了在基于第二代英特尔® 至强® 可扩展处理器的 CPU 服务器上进行推理优 化,并进行了测试。测试数据显示,CPU 服务器在部分场景下能够实现比 GPU 服务器 更高的推理性能,同时在 TCO、部署灵活性等方面更具优势。在计算机视觉领域的强 劲算力需求下,也能够可靠的支撑快速增长的业务需求。
背景:58 同城使用在线推理为用户提供精准服务
58 同城的业务广泛涵盖招聘、房产、车辆、兼职、黄页等海量的生活分类信息,随着 各个业务线业务的蓬勃发展,58 同城上的分类信息呈现出爆炸性增长的趋势。对不同 场景下的需求做好分类信息处理,已成为一个重要问题。以房产场景为例,用户每天会 上传大量的房源相关图片,系统如何根据用户上传的海量图片信息,精准快速的进行识 别与分类,是提升用户体验、增加业务收益的关键。
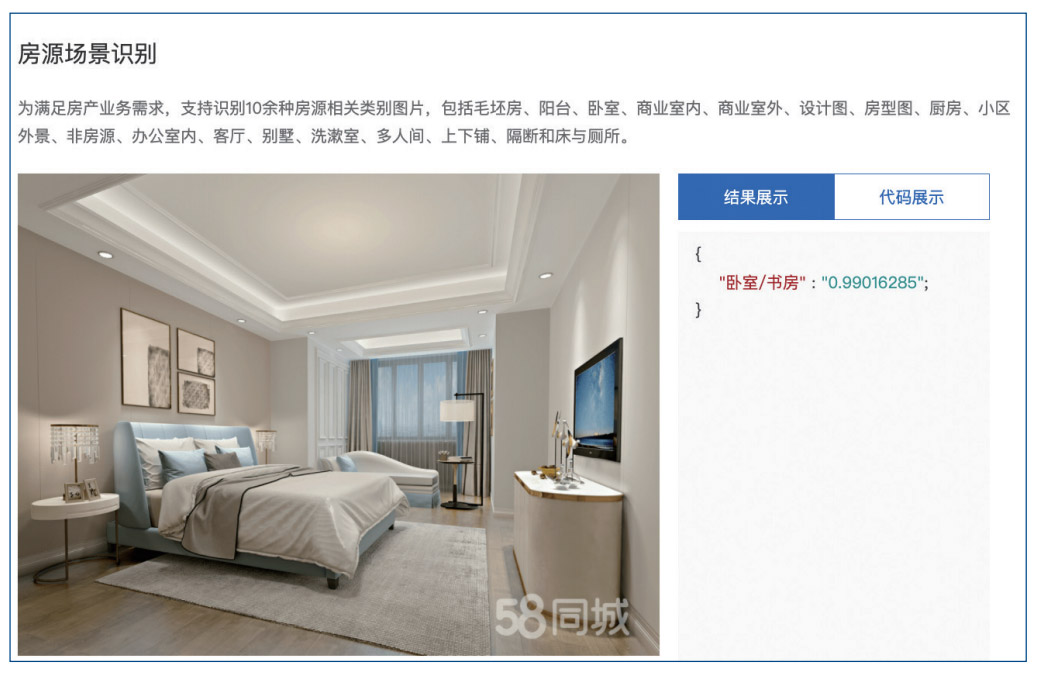
为了提高深度学习平台在线推理的性能,同时尽可能降低系统的总体拥有成本(TCO), 目前,基于深度学习模型的预测服务优化已经成为了一个重 要方向。在图像领域的算法模型中,如 ResNet、CRNN、 YOLOv5 等,都对硬件算力有较大的需求。如果采用 GPU 服 务器来进行深度学习模型推理,将涉及到专用 GPU 硬件的采 购,以及配套的搭建、运维等成本,不仅灵活度较低、应用范 围受限,而且也可能会带来较高的 TCO 压力。同时,在 GPU 服务器上进行深度学习推理往往需要复杂的部署、调优过程, 门槛相对较高,难以满足新增应用快速上线的需求。 与 GPU 服务器相比,CPU 服务器具备更强的灵活性、敏捷性, 能够支持大数据、云计算、虚拟化等多种业务的弹性扩展, 方便部署和管理,满足企业不同业务场景的动态资源需求。 此外,通过面向 AI 工作负载的技术特性升级以及性能优化, CPU 已经能够广泛满足用户不同 AI 应用对于算力的要求。 解决方案:英特尔® 至强® 可扩展处理器 + OpenVINO™ 工具套件提升推理性能 为了构建更高效、更具经济性的在线推理系统,58 同城推出 了基于英特尔® 至强® 可扩展处理器的 CPU 推理服务器方案。 该方案除了搭载高性能、面向人工智能应用进行优化的第二代 英特尔® 至强® 可扩展处理器,还通过 OpenVINO™ 工具套件 进行了性能优化,从而进一步发挥性能潜力。 第二代英特尔® 至强® 可扩展处理器内置人工智能加速功能, 并已针对工作负载进行优化,能够为各种高性能计算工作负 载、AI 应用以及高密度基础设施带来一流的性能和内存带宽。
同时,采用矢量神经网络指令(VNNI)的英特尔® 深度学习加 速(英特尔® DL Boost)显著提高了人工智能推理的表现,这使其成为进行深度学习应用的卓越基础设施。
OpenVINO™ 工具套件支持加快部署广泛的深度学习推理应用 和解决方案,可支持开发人员使用行业标准人工智能框架、标 准或自定义层,将深度学习推理轻松集成到应用中,在英特尔® 硬件(包括加速器)中扩展工作负载并改善性能。借助面向 预推理模型的内置模型优化器(Model Optimizer,MO), 和面向专用硬件加速的推理引擎(Inference Engine,IE)运 行时,OpenVINO™ 工具套件可在英特尔不同平台上部署并加 速神经网络模型,能够在保持精度的同时显著提高图像推理速度。
署环境之间的转换,执行静态模型分析并调整深度学习模型, 致力于在终端目标设备上实现最优执行能力。它支持从流行的 框架(包括 TensorFlow/ONNX/模型)到中间数据格式(IR, intermediate representation)的离线模型转换。推理引擎则 提供统一的跨平台 C、C++ 和 Python API,用于推理加速和 优化。
OpenVINO Model Server 是高性能 K8S 容器化的 AI 服务部 署工具,可实现便捷高效的 AI 推理服务部署与运维。该工具 依赖标准的 gPRC 和 RESTful 网络接口,针对不同的 AI 业务 功能,无需重复编写代码,即可实现新模型算法服务上线。该 工具同时集成了高度优化的推理进程,支持英特尔不同硬件平 台资源的调度
验证:50% 以上的推理性能提升
为了验证在 CPU、GPU 等不同平台上进行深度学习推理的性 能以及 TCO 表现,58 同城进行了相应的测试,测试采用了 基于开源的 ResNet50 模型以及基于 Inception 和 ResNet 组 合的 ResNeXt 模型,这两种模型皆应用在 58 同城的实际业 务中。参测的推理服务器分别基于英特尔® 至强® 金牌 6230R 处理器以及 T4 GPU,其中,前者为双路服务器,测试配置如 表 1 所示
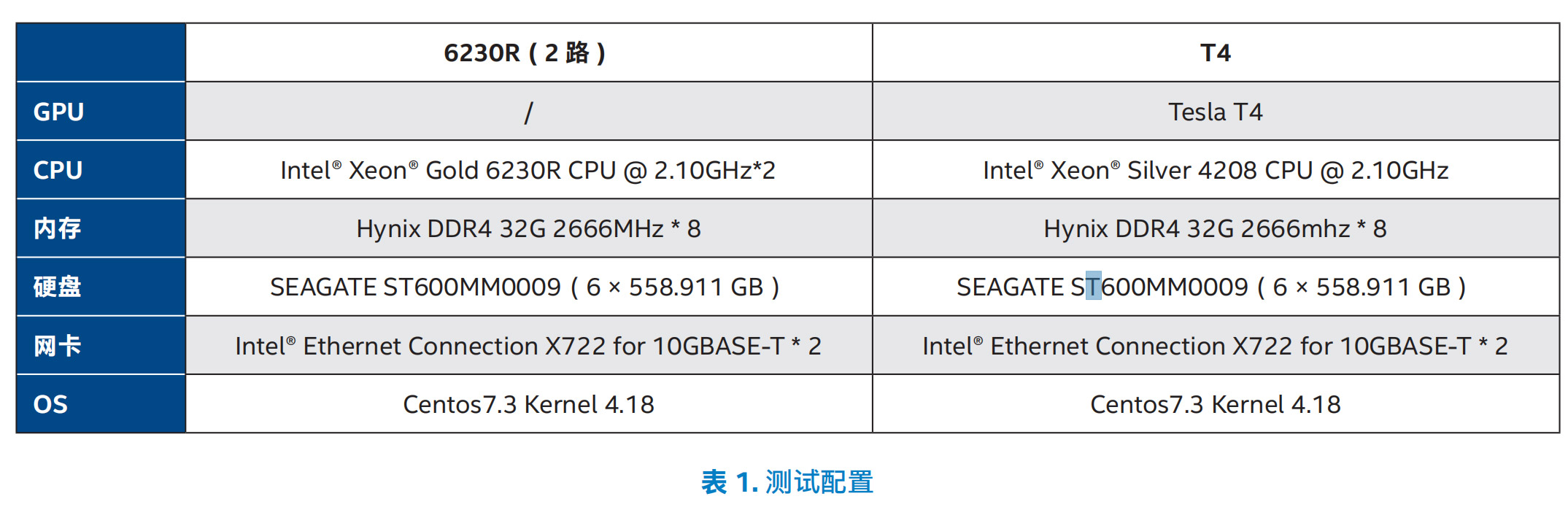
6230R 处理器的平台的 ResNeXt 模型推理性能是基于 GPU 平台性能的 1.56 倍,ResNet50 模型的推理性能则是后者的 1.76 倍,能够满足 58 同城实际业务对于性能与耗时的需求。 同时,CPU 平台通常有着更大的灵活性与动态扩展的敏捷性, 能够帮助 58 同城更好地为多样化场景提供支撑。
 czk634@gzyuqiang.com
czk634@gzyuqiang.com
 134-2756-1409 158-7654-7788
134-2756-1409 158-7654-7788
 广州市天河区石牌西路8号1806房
广州市天河区石牌西路8号1806房



