本文介绍了面向 AI 推理的英特尔® 精选解决方案以及其如何解决 AI 推理部署的痛点,包括其中采用的软件、硬件和技术。该系列解决方案有基础和增强配置,提供灵活的可定制性,以满足不同需求。您可通过阅读本文具体了解如何在符合行业标准的硬件上部署优化的高速人工智能推理,驱动更高商业价值。
越来越多的企业希望借助人工智能 (AI) 以增加收入、提高效率并推动产品创新。尤其需要指出的是,基于深度学习 (DL) 技术的人工智能用例能够带来有效且实用的洞察;其中一些用例可在众多行业推动进步,例如:
这些用例仅仅只是开始。随着企业将人工智能融入业务运营,他们将发现应用人工智能的新方法。然而,所有人工智能用例的商业价值都取决于由深度神经网络训练的模型的推理速度。在深度学习模型上支持推理所需的资源规模可能非常庞大,通常需要企业更新硬件以获得其所需的性能和速度。但是,许多客户希望扩展其现有的基础设施,而不是重新购买单一用途的新硬件。您的 IT 部门已经非常熟悉英特尔® 硬件架构,其灵活性能使您的 IT 投资更高效。面向人工智能推理的英特尔® 精选解决方案是“一站式”平台,提供经过预配置、优化和验证的解决方案,无需另外配置加速卡,即可在 CPU 上实现低时延、高吞吐量的推理。
面向人工智能推理的英特尔® 精选解决方案
面向人工智能推理的英特尔® 精选解决方案能帮助您快速入门,利用基于经验证的英特尔® 架构的解决方案,部署高效的人工智能推理算法,从而加速创新和产品上市。为了加快人工智能应用的推理和上市,面向人工智能推理的英特尔® 精选解决方案结合了多种英特尔及第三方的软硬件技术。
软件选择
面向人工智能推理的英特尔® 精选解决方案使用的软件包括开发人员工具和管理工具,以辅助生产环境中的人工智能推理。
英特尔® 分发版 OpenVINO™ 工具包
英特尔® 分发版开放视觉推理和神经网络优化工具包(即英特尔® 分发版 OpenVINO™ 工具包)是一套开发人员套件,可加速高性能人工智能和深度学习推理的部署。该工具套件可针对多种英特尔® 硬件选项,对各种不同框架训练的模型进行优化,以提供出色性能部署。工具套件中的深度学习工作台 (DL Workbench) 可将模型量化到较低精度。在此过程中,工具套件把使用较大的高精度 32 位浮点数(通常用于训练,会占用较多内存)的模型转换为 8 位整数,以优化内存使用和性能。将浮点数转换为整数能够在保持几乎相同精度的同时,显著提高人工智能推理速度1。该工具套件可以转换和执行在多种框架中构建的模型,包括 TensorFlow、MXNet、PyTorch、Kaldi 和开放神经网络交换 (Open Neural Network Exchange, ONNX) 生态系统所支持的任何框架。此外,用户还可获得经过预训练的公开模型,无需再自行搜寻或训练模型,从而加速基于英特尔® 处理器的开发和图像处理管道优化。
深度学习参考堆栈
面向人工智能推理的英特尔® 精选解决方案配备深度学习参考堆栈 (DLRS)。这是一个集成的高性能开源软件堆栈,已针对英特尔® 至强® 可扩展处理器进行优化,并封装在一个便捷的 Docker 容器中。DLRS 经过预先验证,并且配置完善,已包含所需的库和软件组件,因此有助于降低人工智能在生产环境中与多个软件组件集成所带来的复杂性。该堆栈还包括针对主流深度学习框架 TensorFlow 和 PyTorch 高度调优的容器,以及英特尔® 分发版 OpenVINO™ 工具包。该开源社区版本也有利于确保人工智能开发人员可轻松获得英特尔® 平台的所有特性和功能。
Kubeflow 和 Seldon Core
随着企业和机构不断积累在生产环境中部署推理模型的经验,业界逐步形成了一系列最佳实践的共识,即 “MLOps”,类似于 “DevOps” 软件开发实践。为了帮助团队应用 MLOps,面向人工智能推理的英特尔® 精选解决方案使用 Kubeflow。借助 Kubeflow,团队可在“零停机”的情况下顺利推出模型的新版本。Kubeflow 使用受到支持的模型服务后端(例如 TensorFlow Serving)将经过训练的模型导出到 Kubernetes。模型部署则可使用金丝雀测试或影子部署来实现新旧版本的并行验证。如果发现问题,除了进行跟踪,团队还可以使用模型和数据版本控制来简化根本原因分析。
为了在需求增加时保持快捷响应的服务,面向人工智能推理的英特尔® 精选解决方案提供负载平衡功能,能够跨节点将推理自动分片到可服务对象的可用实例中。多租户支持提供不同的模型,从而提高硬件利用率。最后,为了在运行人工智能推理的服务器和需要人工智能洞察的端点之间加速处理推理请求,面向人工智能推理的英特尔® 精选解决方案可以使用 Seldon Core 来帮助管理推理管道。Kubeflow 还与 Seldon Core 集成,从而在 Kubernetes 上部署深度学习模型,并使用 Kubernetes API 来管理部署在推理管道中的容器。
硬件选择
面向人工智能推理的英特尔® 精选解决方案结合了第二代英特尔® 至强® 可扩展处理器、英特尔® 傲腾™ 固态盘 (SSD)、英特尔® 3D NAND 固态盘和英特尔® 以太网 700 系列,因此您的企业可以在性能经过优化的平台上快速部署生产级人工智能基础设施,为要求严苛的应用和工作负载提供大内存容量。
第二代英特尔® 至强® 可扩展处理器
面向人工智能推理的英特尔® 精选解决方案具有第二代英特尔® 至强® 可扩展处理器的性能和功能。对于“基础”配置,英特尔® 至强® 金牌 6248 处理器在价格、性能和集成技术之间实现了出色的平衡,能够增强人工智能模型上的推理性能与效率。“增强”配置则采用专为实现更快人工智能推理而设计的英特尔® 至强® 铂金 8268 处理器。此外,在任一配置中也可选用更高型号的处理器。第二代英特尔® 至强® 可扩展处理器包含英特尔® 深度学习加速技术。这是一系列加速功能,可通过专门的矢量神经网络指令 (VNNI) 集来提高人工智能推理性能。该指令集使用一条单独指令即可完成之前需要三条单独指令才能进行的深度学习计算。
英特尔® 傲腾™ 技术
英特尔® 傲腾™ 技术填补了存储和内存层之间的重要空白,让数据中心能够更快地获取数据。这项技术颠覆了内存和存储层,能够在各种不同产品和解决方案中提供持久内存、大型内存池、高速缓存和存储。
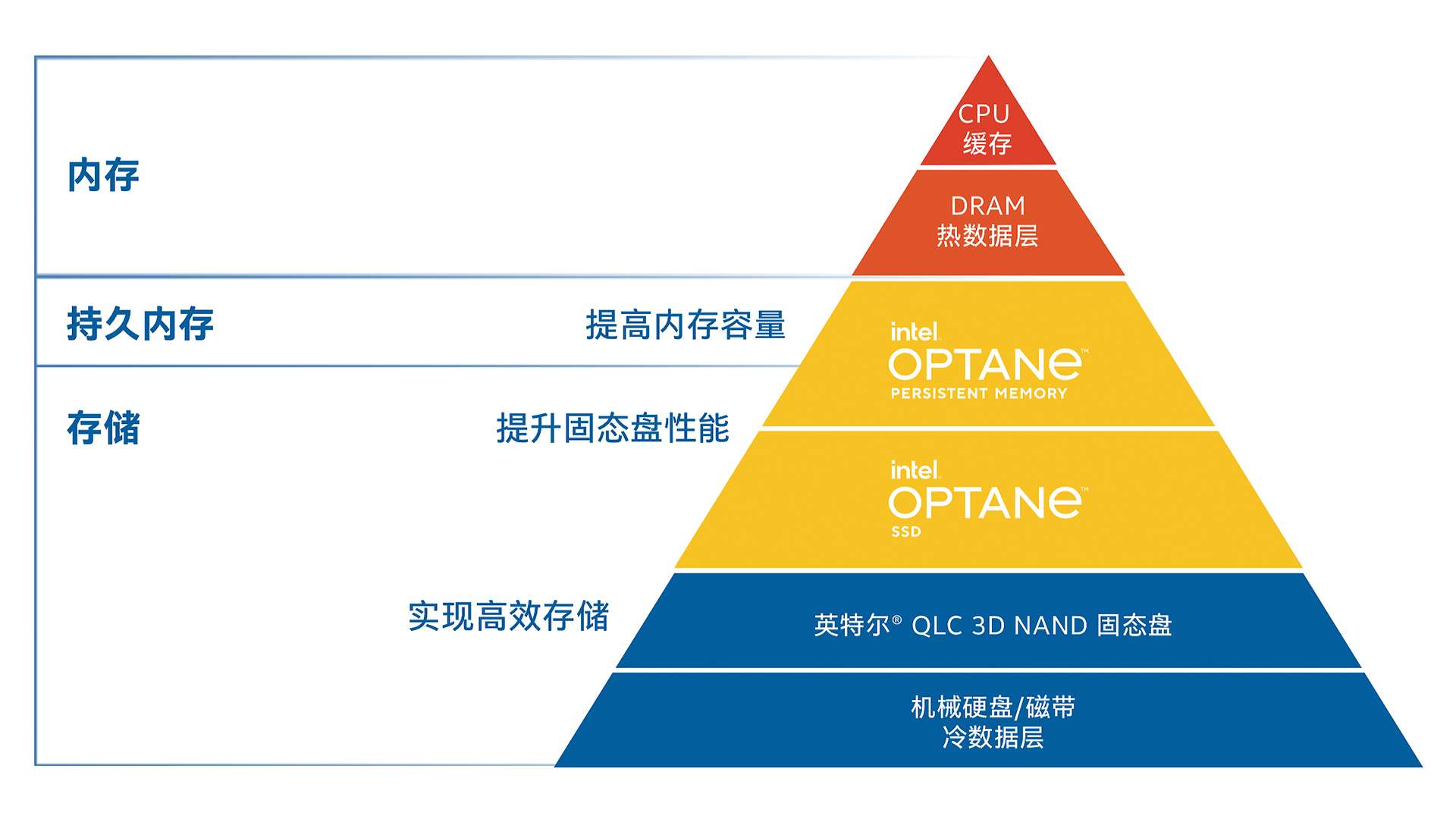
图 1. 英特尔® 傲腾™ 技术填补了数据中心内存和存储之间的性能空白
英特尔® 傲腾™ 固态盘和英特尔® 3D NAND 固态盘
当缓存层运行在具备低时延和高耐用性的高速固态盘上时,人工智能推理更能充分发挥其性能。如缓存层采用高性能固态盘而非主流串行 ATA (SATA) 固态盘,则要求高性能的工作负载将受益匪浅。在英特尔® 精选解决方案中,缓存层采用英特尔® 傲腾™ 固态盘。英特尔® 傲腾™ 固态盘单位成本可提供较高的每秒读写次数 (IOPS),且具备低时延和高耐用性,再加上高达 30 次的每日整盘写入次数 (DWPD),是写入密集型缓存功能的理想选择2。容量层则采用英特尔® 3D NAND 固态盘,可提供出色的读取性能,并兼具数据完整性、性能一致性和驱动可靠性。
25 Gb 以太网
25 Gb 英特尔® 以太网 700 系列网络适配器能够提升面向人工智能推理的英特尔® 精选解决方案的性能。与使用 1 Gb 以太网 (GbE) 适配器和英特尔® 固态盘 DC S4500 相比,使用 25 Gb 以太网适配器配合第二代英特尔® 至强® 铂金处理器和英特尔® 固态盘 DC P4600 可提供高达前者 2.5 倍的性能34。英特尔® 以太网 700 系列提供经过验证的性能;其广泛的互操作性可在数据弹性和服务可靠性方面满足高质量阈值5。所有英特尔® 以太网产品均提供全球售前和售后支持,并在产品周期内提供有限质保。
经过基准测试验证的性能
所有英特尔® 精选解决方案均通过基准测试验证,已满足预先指定的工作负载优化性能的最低功能级别。在数据中心、网络边缘和云中的各类工作负载中,人工智能推理正逐渐成为其重要组成部分,因此英特尔选择使用标准的深度学习基准测试方法,并模拟真实场景进行测量和基准测试。
在标准基准测试中,每秒可处理的图像数量(即吞吐量)是在一个经过预先训练的深度残差神经网络 (ResNet 50 v1) 上测量的。该神经网络与使用合成数据的 TensorFlow、PyTorch 和 OpenVINO™ 工具套件上广泛使用的深度学习用例(如图像分类、定位和检测)密切相关。
为了模拟真实场景,测试启动了多个客户端,以模拟多个请求流。这些客户端将图像从外部客户端系统发送到服务器以进行推理。在服务器端,入站请求由 Istio 进行负载平衡。然后,请求将发送到一个可服务对象的多个实例,该对象包含通过 Seldon Core 运行的一条预处理、预测和后处理步骤管道。预测使用 OpenVINO™ 工具包中 Model Server 经过优化的 DLRS 容器映像完成。在请求通过管道后,推理结果将返回给提出请求的客户端。在此过程中测量出的吞吐量和时延可帮助确保此测试配置足以支持生产环境中的推理规模。
基础配置和增强配置
我们以两种参考配置(“基础配置”和“增强配置”)向您展示面向人工智能推理的英特尔® 精选解决方案。两者均已经过验证,可提供出色性能。这两种配置经过专门的设计和预测试,可提供出众的价值、性能、安全性和用户体验。最终客户也可与系统构建商、系统集成商,或是解决方案和服务提供商合作,根据企业和机构的需求与预算来定制这些配置。
“基础配置”具有出色的性价比,且已针对人工智能推理工作负载进行优化。“增强配置”使用高于“基础配置”的英特尔® 至强® 可扩展处理器型号,并增加一倍内存。表 1 列出了这两种配置的详细信息。
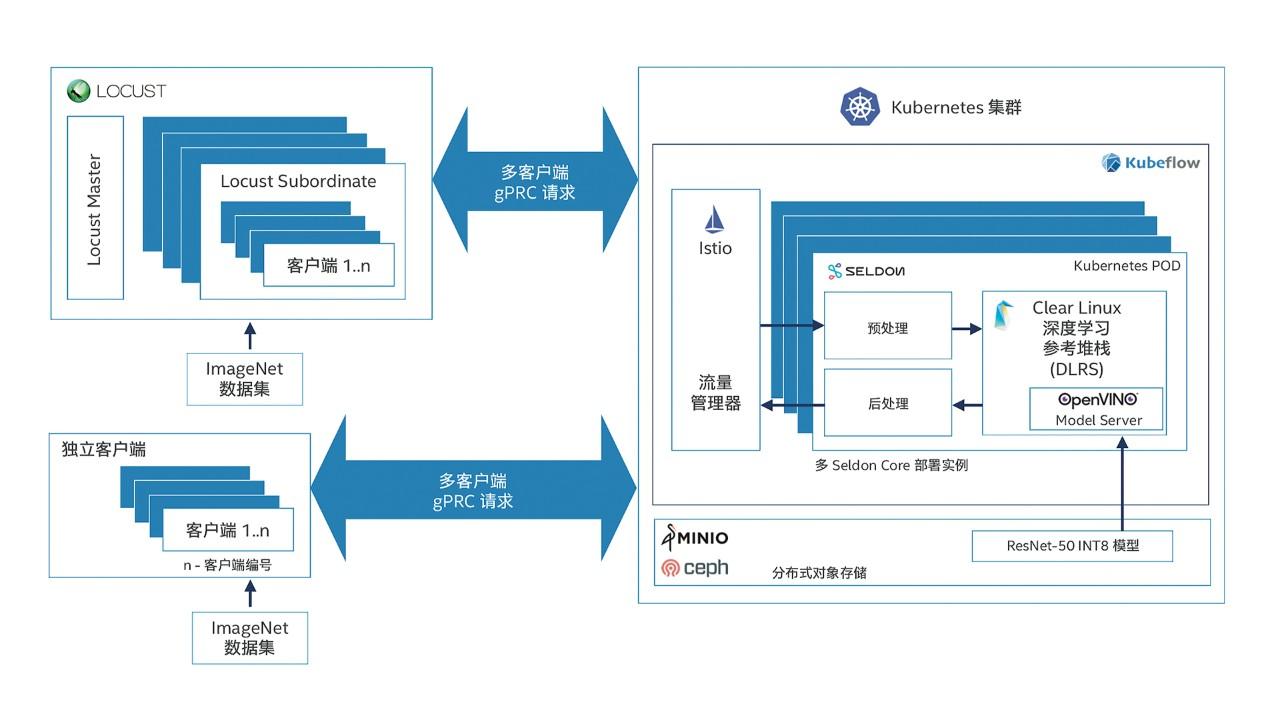
图 2. 在面向人工智能推理的英特尔® 精选解决方案上进行的真实场景基准测试架构图
 czk634@gzyuqiang.com
czk634@gzyuqiang.com
 134-2756-1409 158-7654-7788
134-2756-1409 158-7654-7788
 广州市天河区石牌西路8号1806房
广州市天河区石牌西路8号1806房



